什么是C++多线程并发
- 线程
- 多线程并发
多线程并发即多个线程同时执行,一般而言,多线程并发就是把一个任务拆分为多个子任务,然后交由不同线程处理不同子任务,使得这多个子任务同时执行
- C++多线程并发
实现C++多线程并发程序的思路如下:将任务的不同功能交由多个函数分别实现,创建多个线程,每个线程执行一个函数,一个任务就这样同时分由不同线程执行了。
什么时候不适用多线程并发
- 每创建一个线程,系统要分配给线程相应的栈空间,用于保存上下文信息.
- 如果线程执行过快导致上下文切换频繁,这将导致收益比不上成本
C++多线程并发基础知识
创建线程
std::ref和std::cref /std::bind
- std::ref 用于包装按引用传递的值
- std::cref 用于包装按const引用传递的值
为什么线程函数不能传引用
- C++传递参数给线程函数时出现问题?
C++封装thread是通过将thread entry functor和所有的参数打包到一个数据结构里,然后通过库中的一个预先写好的OS compatible thread entry function启动线程,在这个函数中将传进去的数据结构解包再运行。
这个过程需要将所有的参数copy/move一份,而众所周知引用本身是不能copy/move的,所以C++在标准库里加入了std::reference_wrapper,这个东西其实很无聊,就是把引用变成指针存起来,用的时候再转成引用,但这样就解决了引用不能copy/move的问题,因为指针是可以copy的,而std::ref/std::cref就是返回std::reference_wrapper的builder function。
使用方法
//创建线程
std::thread THREAD_NAME(FUNCTION_NAME,PARAM...);
//当线程启动后,一定要在和线程相关联的std::thread对象销毁前,对线程运用join()或者detach()方法。
//当使用join()函数时,主调线程阻塞,等待被调线程终止,然后主调线程回收被调线程资源,并继续运行;
THREAD_NAME::join();
//当使用detach()函数时,主调线程继续运行,被调线程驻留后台运行,主调线程无法再取得该被调线程的控制权。当主调线程结束时,由运行时库负责清理与被调线程相关的资源。
THREAD_NAME::detach();
//joinable()函数是一个布尔类型的函数,他会返回一个布尔值来表示当前的线程是否是可执行线程(能被join或者detach),因为相同的线程不能join两次,也不能join完再detach,同理也不能detach,所以joinable函数就是用来判断当前这个线程是否可以joinable的。
THREAD_NAME::joinable();
#include<iostream>
#include<thread>
using namespace std;
void proc(int &a)
{
cout << "我是子线程,传入参数为" << a << endl;
cout << "子线程中显示子线程id为" << this_thread::get_id()<< endl;
}
int main()
{
cout << "我是主线程" << endl;
int a = 9;
thread th2(proc,ref(a));//第一个参数为函数名,第二个参数为该函数的第一个参数,如果该函数接收多个参数就依次写在后面。此时线程开始执行。
th2.join();//此时主线程被阻塞直至子线程执行结束。
cout << "主线程中显示子线程id为" << th2.get_id() << endl;
return 0;
}
创建线程时的传参问题分析
- 创建线程时需要传递函数名作为参数,提供的函数对象会复制到新的线程的内存空间中执行与调用。
- 在传参过程中,std::thread的构造函数会拷贝传入的参数
- 当传入参数为基本数据类型(int,char,string等)时,会拷贝一份给创建的线程;
- 当传入参数为指针时,会浅拷贝一份给创建的线程,也就是说,只会拷贝对象的指针,不会拷贝指针指向的对象本身。
- 当传入的参数为引用时,实参必须用ref()函数处理后传递给形参,否则编译不通过,此时不存在“拷贝”行为
- 引用只是变量的别名,在线程中传递对象的引用,那么该对象始终只有一份,只是存在多个别名罢了
- 对于std::ref,其底层相当于拷贝指针,但是在解释的时候,使用引用解释.
互斥量(锁)使用
什么是互斥量(锁)
- 在访问共享数据时,代码进入临界区,对于多个线程需要互斥访问这时候需要使用互斥量(锁)
互斥量是为了解决数据共享过程中可能存在的访问冲突的问题
死锁
临界区、信号量、互斥量(锁)的区别与联系:
- 共同点:
- 三者都可以用来进行进程的同步与互斥
- 不同点:
- 临界区:速度最快,但只能作用于同一进程下不同线程,不能作用于不同进程;临界区可确保某一代码段同一时刻只被一个线程执行;
- 信号量:多个线程同一时刻访问共享资源,进行线程的计数,确保同时访问资源的线程数目不超过上限,当访问数超过上限后,不发出信号量;
- 互斥量:比临界区满,但支持不同进程间的同步与互斥
同步与互斥
- 任务运行时,有些任务片段间存在严格的先后顺序,同步指维护任务片段的先后顺序;
- 互斥就是保证资源同一时刻只能被一个进程使用;互斥是为了保证数据的一致性
锁的类型
互斥锁
- 互斥量mutex就是互斥锁,加锁的资源支持互斥访问;
读写锁
- shared_mutex读写锁把对共享资源的访问者划分成读者和写者,多个读线程能同时读取共享资源,但只有一个写线程能同时读取共享资源
- shared_mutex通过lock_shared,unlock_shared进行读者的锁定与解锁;通过lock,unlock进行写者的锁定与解锁。
shared_mutex s_m;
std::string book;
void read()
{
s_m.lock_shared();
cout << book;
s_m.unlock_shared();
}
void write()
{
s_m.lock();
book = "new context";
s_m.unlock();
}
自旋锁
- 如果自旋锁已经被别的执行单元保持,调用者就一直循环在那里看是否该自旋锁的保持者已经释放了锁;
- 自旋锁比较适用于锁使用者保持锁时间比较短的情况。
C++多线程相关函数
- 进入代码临界区的时候需要进行加锁
加锁-lock()与unlock()
mutex m表示实例化mutex变量,用于加锁.- 如果该互斥量当前未上锁,则本线程将该互斥量锁住,直到调用unlock()之前,本线程一直拥有该锁
- 如果该互斥量当前被其他线程锁住,则本线程被阻塞,直至该互斥量被其他线程解锁,此时本线程将该互斥量锁住,直到调用unlock()之前,本线程一直拥有该锁
- 缺点
- 如果忘记unlock(),将导致锁无法释放
#include<iostream>
#include<thread>
#include<mutex>
using namespace std;
mutex m;//实例化m对象,不要理解为定义变量
void proc1(int a)
{
m.lock();
cout << "proc1函数正在改写a" << endl;
cout << "原始a为" << a << endl;
cout << "现在a为" << a + 2 << endl;
m.unlock();
}
void proc2(int a)
{
m.lock();
cout << "proc2函数正在改写a" << endl;
cout << "原始a为" << a << endl;
cout << "现在a为" << a + 1 << endl;
m.unlock();
}
int main()
{
int a = 0;
thread t1(proc1, a);
thread t2(proc2, a);
t1.join();
t2.join();
return 0;
}
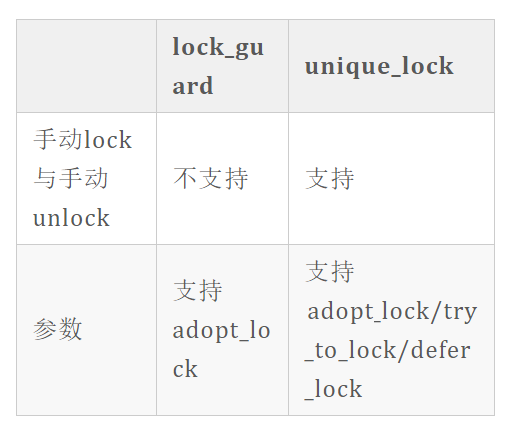
加锁-lock_guard()
- 声明一个局部的std::lock_guard对象,在其构造函数中进行加锁,在其析构函数中进行解锁
- 创建即加锁,作用域结束自动解锁
#include<iostream>
#include<thread>
#include<mutex>
using namespace std;
mutex m;//实例化m对象,不要理解为定义变量
void proc1(int a)
{
lock_guard<mutex> g1(m);//用此语句替换了m.lock();lock_guard传入一个参数时,该参数为互斥量,此时调用了lock_guard的构造函数,申请锁定m
cout << "proc1函数正在改写a" << endl;
cout << "原始a为" << a << endl;
cout << "现在a为" << a + 2 << endl;
}//此时不需要写m.unlock(),g1出了作用域被释放,自动调用析构函数,于是m被解锁
void proc2(int a)
{
{
lock_guard<mutex> g2(m);
cout << "proc2函数正在改写a" << endl;
cout << "原始a为" << a << endl;
cout << "现在a为" << a + 1 << endl;
}//通过使用{}来调整作用域范围,可使得m在合适的地方被解锁
cout << "作用域外的内容3" << endl;
cout << "作用域外的内容4" << endl;
cout << "作用域外的内容5" << endl;
}
int main()
{
int a = 0;
thread t1(proc1, a);
thread t2(proc2, a);
t1.join();
t2.join();
return 0;
}
- adopt_lock标识表示构造函数中不再进行互斥量锁定,因此此时需要提前手动锁定
#include<iostream>
#include<thread>
#include<mutex>
using namespace std;
mutex m;//实例化m对象,不要理解为定义变量
void proc1(int a)
{
m.lock();//手动锁定
lock_guard<mutex> g1(m,adopt_lock);
cout << "proc1函数正在改写a" << endl;
cout << "原始a为" << a << endl;
cout << "现在a为" << a + 2 << endl;
}//自动解锁
void proc2(int a)
{
lock_guard<mutex> g2(m);//自动锁定
cout << "proc2函数正在改写a" << endl;
cout << "原始a为" << a << endl;
cout << "现在a为" << a + 1 << endl;
}//自动解锁
int main()
{
int a = 0;
thread t1(proc1, a);
thread t2(proc2, a);
t1.join();
t2.join();
return 0;
}
加锁-unique_lock()
#include<iostream>
#include<thread>
#include<mutex>
using namespace std;
mutex m;
void proc1(int a)
{
unique_lock<mutex> g1(m, defer_lock);//始化了一个没有加锁的mutex
cout << "xxxxxxxx" << endl;
g1.lock();//手动加锁,注意,不是m.lock();注意,不是m.lock(),m已经被g1接管了;
cout << "proc1函数正在改写a" << endl;
cout << "原始a为" << a << endl;
cout << "现在a为" << a + 2 << endl;
g1.unlock();//临时解锁
cout << "xxxxx" << endl;
g1.lock();
cout << "xxxxxx" << endl;
}//自动解锁
void proc2(int a)
{
unique_lock<mutex> g2(m, try_to_lock);//尝试加锁一次,但如果没有锁定成功,会立即返回,不会阻塞在那里,且不会再次尝试锁操作。
if (g2.owns_lock()) {//锁成功
cout << "proc2函数正在改写a" << endl;
cout << "原始a为" << a << endl;
cout << "现在a为" << a + 1 << endl;
}
else {//锁失败则执行这段语句
cout << "" << endl;
}
}//自动解锁
int main()
{
int a = 0;
thread t1(proc1, a);
t1.join();
//thread t2(proc2, a);
//t2.join();
return 0;
}
std::unique_lock所有权的转移
mutex m;
{
unique_lock<mutex> g2(m,defer_lock);
unique_lock<mutex> g3(move(g2));//所有权转移,此时由g3来管理互斥量m
g3.lock();
g3.unlock();
g3.lock();
}
线程同步 - condition_variable
- std::condition_variable对象的作用不是用来管理互斥量的,它的作用是用来同步线程
它的用法相当于编程中常见的flag标志
wait函数需要传入一个std::mutex(一般会传入std::unique_lock对象),即上述的locker。wait函数会自动调用 locker.unlock() 释放锁(因为需要释放锁,所以要传入mutex)并阻塞当前线程,本线程释放锁使得其他的线程得以继续竞争锁。一旦当前线程获得notify(通常是另外某个线程调用 notify_* 唤醒了当前线程),wait() 函数此时再自动调用 locker.lock()上锁。
cond.notify_one(): 随机唤醒一个等待的线程
cond.notify_all(): 唤醒所有等待的线程
std::wait(MUTEX_NAME)异步线程
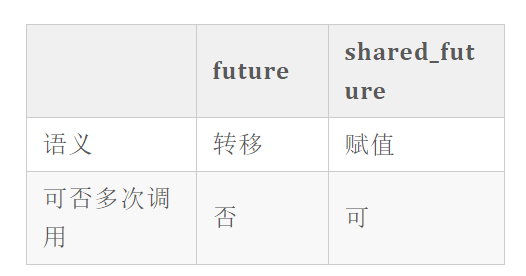
async与future
- std::async是一个函数模板,用来启动一个异步任务,它返回一个std::future类模板对象
- future对象起到了占位的作用,调用std::future对象的get()成员函数时,主线程会被阻塞直到异步线程执行结束,并把返回结果传递给std::future,即通过FutureObject.get()获取函数返回值
```cppinclude
include
include
include
include
using namespace std;
double t1(const double a, const double b)
{
double c = a + b;
Sleep(3000);//假设t1函数是个复杂的计算过程,需要消耗3秒
return c;
}
int main()
{
double a = 2.3;
double b = 6.7;
future
cout << “正在进行计算” << endl;
cout << “计算结果马上就准备好,请您耐心等待” << endl;
cout << “计算结果:” << fu.get() << endl;//阻塞主线程,直至异步线程return
//cout << “计算结果:” << fu.get() << endl;//取消该语句注释后运行会报错,因为future对象的get()方法只能调用一次。
return 0;
}
### shared_future
## 原子类型atomic<>
* 原子操作指“不可分割的操作”
* 互斥量的加锁一般是针对一个代码段,而原子操作针对的一般都是一个变量(操作变量时加锁防止他人干扰)
* std::atomic<>是一个模板类,使用该模板类实例化的对象,提供了一些保证原子性的成员函数来实现共享数据的常用操作
> std::atomic<>用来定义一个自动加锁解锁的共享变量,供多个线程访问而不发生冲突。
> std::atomic<>对象提供了常见的原子操作:store,load,exchange,++,–,+=,-=,&=,|=,^=等
# 生产者消费者问题
* 生产者用于生产数据,生产一个就往共享数据区存一个,如果共享数据区已满的话,生产者就暂停生产,等待消费者的通知后再启动。
* 消费者用于消费数据,一个一个的从共享数据区取,如果共享数据区为空的话,消费者就暂停取数据,等待生产者的通知后再启动。
```cpp
#include<iostream>
#include<thread>
#include<mutex>
#include<queue>
#include<condition_variable>
using namespace std;
//缓冲区存储的数据类型
struct CacheData
{
//商品id
int id;
//商品属性
string data;
};
queue<CacheData> Q;
//缓冲区最大空间
const int MAX_CACHEDATA_LENGTH = 10;
//互斥量,生产者之间,消费者之间,生产者和消费者之间,同时都只能一个线程访问缓冲区
mutex m;
condition_variable condConsumer;
condition_variable condProducer;
//全局商品id
int ID = 1;
//消费者动作
void ConsumerActor()
{
unique_lock<mutex> lockerConsumer(m);
cout << "[" << this_thread::get_id() << "] 获取了锁" << endl;
while (Q.empty())
{
cout << "因为队列为空,所以消费者Sleep" << endl;
cout << "[" << this_thread::get_id() << "] 不再持有锁" << endl;
//队列空, 消费者停止,等待生产者唤醒
condConsumer.wait(lockerConsumer);
cout << "[" << this_thread::get_id() << "] Weak, 重新获取了锁" << endl;
}
cout << "[" << this_thread::get_id() << "] ";
CacheData temp = Q.front();
cout << "- ID:" << temp.id << " Data:" << temp.data << endl;
Q.pop();
condProducer.notify_one();
cout << "[" << this_thread::get_id() << "] 释放了锁" << endl;
}
//生产者动作
void ProducerActor()
{
unique_lock<mutex> lockerProducer(m);
cout << "[" << this_thread::get_id() << "] 获取了锁" << endl;
while (Q.size() > MAX_CACHEDATA_LENGTH)
{
cout << "因为队列为满,所以生产者Sleep" << endl;
cout << "[" << this_thread::get_id() << "] 不再持有锁" << endl;
//对列慢,生产者停止,等待消费者唤醒
condProducer.wait(lockerProducer);
cout << "[" << this_thread::get_id() << "] Weak, 重新获取了锁" << endl;
}
cout << "[" << this_thread::get_id() << "] ";
CacheData temp;
temp.id = ID++;
temp.data = "*****";
cout << "+ ID:" << temp.id << " Data:" << temp.data << endl;
Q.push(temp);
condConsumer.notify_one();
cout << "[" << this_thread::get_id() << "] 释放了锁" << endl;
}
//消费者
void ConsumerTask()
{
while(1)
{
ConsumerActor();
}
}
//生产者
void ProducerTask()
{
while(1)
{
ProducerActor();
}
}
//管理线程的函数
void Dispatch(int ConsumerNum, int ProducerNum)
{
vector<thread> thsC;
for (int i = 0; i < ConsumerNum; ++i)
{
thsC.push_back(thread(ConsumerTask));
}
vector<thread> thsP;
for (int j = 0; j < ProducerNum; ++j)
{
thsP.push_back(thread(ProducerTask));
}
for (int i = 0; i < ConsumerNum; ++i)
{
if (thsC[i].joinable())
{
thsC[i].join();
}
}
for (int j = 0; j < ProducerNum; ++j)
{
if (thsP[j].joinable())
{
thsP[j].join();
}
}
}
int main()
{
//一个消费者线程,5个生产者线程,则生产者经常要等待消费者
Dispatch(1,5);
return 0;
}
C++多线程并发高级知识
线程池
- 不采用线程池时
创建线程 -> 由该线程执行任务 -> 任务执行完毕后销毁线程。即使需要使用到大量线程,每个线程都要按照这个流程来创建、执行与销毁。
虽然创建与销毁线程消耗的时间 远小于 线程执行的时间,但是对于需要频繁创建大量线程的任务,创建与销毁线程 所占用的时间与CPU资源也会有很大占比。
- 采用线程池
减少创建与销毁线程所带来的时间消耗与资源消耗
程序启动后,预先创建一定数量的线程放入空闲队列中,这些线程都是处于阻塞状态,基本不消耗CPU,只占用较小的内存空间。
接收到任务后,任务被挂在任务队列,线程池选择一个空闲线程来执行此任务。
任务执行完毕后,不销毁线程,线程继续保持在池中等待下一次的任务。
线程池解决的问题
- 需要频繁创建与销毁大量线程的情况下,由于线程预先就创建好了,接到任务就能马上从线程池中调用线程来处理任务,减少了创建与销毁线程带来的时间开销和CPU资源占用。
- ) 需要并发的任务很多时候,无法为每个任务指定一个线程(线程不够分),使用线程池可以将提交的任务挂在任务队列上,等到池中有空闲线程时就可以为该任务指定线程。